1. cube
HR
select department_id, count(*)
from employees
group by rollup(department_id);
select decode(grouping(department_id), 0, nvl(to_char(department_id), '인턴')
, '전체') AS 부서번호
, decode(grouping(GENDER), 0, GENDER
, '전체') AS 성별
, count(*) AS 인원수
, round(count(*)/(select count(*) from employees)*100, 1) AS "퍼센티지(%)"
from
(
select department_id
, case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS GENDER
from employees
) V
group by cube(department_id, GENDER)
order by 1;

2. grouping sets
HR
select department_id
, GENDER
, count(*)
from
(
select department_id
, case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS GENDER
from employees
) V
group by grouping sets ((department_id, GENDER), (department_id), ());
3. truncate
-- delete는 어떤 테이블에 있는 특정 행 또는 모든 행들을 삭제하는 것이고, 수동 commit이므로 rollback이 가능하다.
-- truncate table 특정테이블명; 은 특정테이블명에 있는 모든 행들을 삭제하는 것이고, 자동(auto) commit이므로 rollback이 불가하다.
-- truncate table 특정테이블명; 을 하면 특정테이블명이 생성되었을 시로 완전히 초기화가 된다.
Ⅰ. 누적
HR
sum(누적되어야할 컬럼명) over(order by 누적되어질 기준이 되는 컬럼명 asc[desc])
또는
HR
sum(누적되어야할 컬럼명) over(partition by 그룹화되어질 컬럼명 order by 누적되어질 기준이 되는 컬럼명 asc[desc])
▷ 첫 번째 방법
HR
select jepumname AS 제품명
,to_char(panmaedate, 'yyyy-mm-dd') AS 판매일자
,sum(panmaesu) AS 일판매량
-- , sum(누적되어야할 컬럼명) over(order by 누적되어질 기준이 되는 컬럼명 asc[desc])
, sum(sum(panmaesu)) over(order by to_char(panmaedate, 'yyyy-mm-dd')) AS 누적판매량
from tbl_panmae
where jepumname = '새우깡'
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
order by 판매일자;
▷ 두 번째 방법(인라인 뷰)
HR
select jepumname AS 제품명
,PANMAEDATE AS 판매일자
,DAYTOTAL AS 일판매량
,sum(DAYTOTAL) over(order by PANMAEDATE) AS 누적판매량
from
(
select jepumname
,to_char(panmaedate, 'yyyy-mm-dd') AS PANMAEDATE
,sum(panmaesu) AS DAYTOTAL
from tbl_panmae
where jepumname = '새우깡'
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
)V;

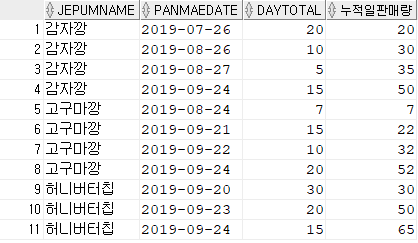
tbl_panmae 테이블에서 모든제품에 대해 일판매량과 누적일 판매량을 나타내세요.
HR
select JEPUMNAME, PANMAEDATE, DAYTOTAL
, sum(DAYTOTAL) over(partition by JEPUMNAME order by PANMAEDATE asc) AS 누적일판매량
from
(
select jepumname
,to_char(panmaedate, 'yyyy-mm-dd') AS PANMAEDATE
, sum(panmaesu) AS DAYTOTAL
from tbl_panmae
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
) V;

새우깡을 제외한 나머지를 나타내 보세요.
HR
select JEPUMNAME, PANMAEDATE, DAYTOTAL
, sum(DAYTOTAL) over(partition by JEPUMNAME order by PANMAEDATE asc) AS 누적일판매량
from
(
select jepumname
,to_char(panmaedate, 'yyyy-mm-dd') AS PANMAEDATE
, sum(panmaesu) AS DAYTOTAL
from tbl_panmae
where jepumname != '새우깡'
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
) V;
문제 ▷▷ employees 테이블에서 아래와 같이 나오도록 하세요.

HR
select department_id
,남자인원수
,여자인원수
,남자인원수+여자인원수 AS 총인원수
from
(
select department_id
, sum (case when substr(jubun, 7, 1) in('1','3') then 1 else 0 end) AS 남자인원수
, sum (case when substr(jubun, 7, 1) in('2','4') then 1 else 0 end) AS 여자인원수
from employees
group by department_id
order by department_id
)V;
Ⅱ. SUB Query
employees 테이블에서 기본급여가 제일 많은 사원과 기본급여가 제일 적은 사원의 정보를 사원번호, 사원명, 기본급여로 나타내세요.
HR
select employee_id AS 사원번호
, first_name || ' ' || last_name AS 사원명
, salary as 기본급여
from employees
where salary = (select max(salary) from employees) OR
salary = (select min(salary) from employees);

문제 ▷▷ employees 테이블에서 부서번호가 60번, 80번 부서에 근무하는 사원들 중에 월급이 50번 부서 직원들의 "평균월급" 보다 많은 사원들만 부서번호, 사원번호, 사원명, 월급을 나타내세요.
HR
select department_id AS 부서번호
,employee_id AS 사원번호
,first_name || ' ' || last_name AS 사원명
,nvl(salary+salary*commission_pct, salary) AS 월급
from employees
where department_id in(60, 80) and
nvl(salary+salary*commission_pct, salary) > (select avg(nvl(salary+salary*commission_pct, salary)) from employees where department_id = 50)
order by department_id;

Ⅲ. Pairwise Query(쌍 서브쿼리)
employees 테이블에서 부서번호별로 salary가 최대인 사원과 부서번호별로 salary가 최소인 사원의 부서번호, 사원번호, 사원명, 기본급여를 나타내세요.
HR
select department_id AS 부서번호
,employee_id AS 사원번호
,first_name || ' ' || last_name AS 사원명
,salary AS 기본급여
from employees
where (department_id, salary) in (select department_id, min(salary)
from employees
group by department_id)
OR (department_id, salary) in (select department_id, max(salary)
from employees
group by department_id)
order by department_id, salary;

문제 ▷▷ 부서번호가 null인 Kimberely Grant를 추가하여 나타내세요.
HR
select nvl(to_char(department_id),'인턴') AS 부서번호
,employee_id AS 사원번호
,first_name || ' ' || last_name AS 사원명
,salary AS 기본급여
from employees
where (nvl(to_char(department_id),-9999), salary) in (select nvl(to_char(department_id),-9999), min(salary)
from employees
group by department_id)
OR (nvl(to_char(department_id),-9999), salary) in (select nvl(to_char(department_id),-9999), max(salary)
from employees
group by department_id)
order by department_id, salary;
-- 만약에 데이터베이스 서버가 MS-SQL Server라면 Pairwise Sub Query(쌍 서브쿼리)가 없다. 그러므로 아래와 같은 형태로 구하면 된다.
HR
select department_id AS 부서번호
,employee_id AS 사원번호
,first_name || ' ' || last_name AS 사원명
,salary AS 기본급여
from employees
where department_id || salary in (select department_id || min(salary)
from employees
group by department_id)
OR department_id || salary in (select department_id || max(salary)
from employees
group by department_id)
order by department_id, salary;

Ⅳ. 상관서브쿼리(== 서브상관쿼리)
-- 상관서브쿼리 이라함은 Main Query(==외부쿼리)에서 사용된 테이블(뷰)에 존재하는 컬럼이 Sub Query(==내부쿼리)의 조건절(where절, having절)에 사용되어지는 것을 말한다.
상관서브쿼리를 사용하여 전체 등수를 구해 보세요.
HR
select E.department_id AS 부서번호
, E.first_name || ' ' || E.last_name AS 사원명
, E.salary AS 기본급여
, ( select count(*) + 1
from employees
where salary > E.salary )AS 전체등수
from employees E
order by 3 desc;

부서내 등수를 구해 보세요.
HR
select department_id AS 부서번호
, first_name || ' ' || last_name AS 사원명
, salary AS 기본급여
, ( select count(*) + 1
from employees
where department_id = E.department_id and
salary > E.salary )AS 부서내등수
, ( select count(*) + 1
from employees
where salary > E.salary )AS 전체등수
from employees E
order by 1, 3 desc;

문제1 ▷▷ 누적을 상관서브쿼리를 사용하여 나타내어 보세요.
HR
select jepumname, PANMAEDATE, DAYTOTAL
,( select sum(sum(panmaesu))
from tbl_panmae
where jepumname = '새우깡' AND
to_char(panmaedate, 'yyyy-mm-dd') <= V.PANMAEDATE
group by to_char(panmaedate, 'yyyy-mm-dd')) AS 누적판매량
from
(
select jepumname
,to_char(panmaedate, 'yyyy-mm-dd') AS PANMAEDATE
,sum(panmaesu) AS DAYTOTAL
from tbl_panmae
where jepumname = '새우깡'
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
)V
order by 2;

문제2 ▷▷ tbl_panmae 테이블에서 모든 제품에 대한 누적을 상관서브쿼리를 사용하여 나타내어 보세요.
HR
select jepumname, PANMAEDATE, DAYTOTAL
,( select sum(sum(panmaesu))
from tbl_panmae
where jepumname = V.jepumname AND
to_char(panmaedate, 'yyyy-mm-dd') <= V.PANMAEDATE
group by to_char(panmaedate, 'yyyy-mm-dd')) AS 누적판매량
from
(
select jepumname
,to_char(panmaedate, 'yyyy-mm-dd') AS PANMAEDATE
,sum(panmaesu) AS DAYTOTAL
from tbl_panmae
group by jepumname, to_char(panmaedate, 'yyyy-mm-dd')
)V
order by 1, 2;
Sub Query 를 사용하여 테이블 복사하기
HR
create table employees_copy
as
select *
from employees;
select *
from employees_copy;
-- 컬럼과 데이터 값 모두 복사
HR
create table employees_copy2
as
select *
from employees
where 1=2;
select *
from employees_copy2;
-- 데이터 값 말고 컬럼만 복사
HR
update employees set first_name = '몰라'
,last_name = '나'
,salary = 100;
commit;

-- 실수로 where 절을 지정 안 했더니 전체 사원명과 월급을 update 하였다.
HR
update employees E set first_name = (select first_name
from employees_copy
where employee_id = E.employee_id)
,last_name = (select last_name
from employees_copy
where employee_id = E.employee_id)
,salary = (select salary
from employees_copy
where employee_id = E.employee_id)
select *
from employees;
commit;

-- 복사한 내용을 사용하여 다시 백업하였다.
'수업내용' 카테고리의 다른 글
| [Day26][Oracle] Multi Table JOIN / NON-EQUI JOIN / SELF JOIN / Stored VIEW (0) | 2019.09.26 |
|---|---|
| [Day25] [Oracle] SET Operator / UNION / UNION ALL / INTERSECT/ MINUS / JOIN (0) | 2019.09.25 |
| [Day23][Oracle] 그룹함수(집계함수) / group by / having 절 / rollup / grouping (0) | 2019.09.23 |
| [Day22][Oracle] 날짜함수 / 변환함수 / 기타함수 (0) | 2019.09.20 |
| [Day21][Oracle] 날짜함수 / 변환함수 (0) | 2019.09.19 |



