Ⅰ. 그룹함수(집계함수)
1. sum : 합계
2. avg : 평균
3. max : 최대값
4. min : 최소값
5. count : select 되어서 나온 결과물의 행의 개수
6. variance : 분산
-- 분산의 제곱근이 표준편차이다. (평균에서 떨어진 정도)
7. stddev : 표준편차
-- 표준편차의 제곱승이 분산이다. (평균과의 차액)
HR
select salary, sum(salary)
from employees;

-- salary 값은 107개, sum 값은 1개이기 때문에 테이블 모양이 다르므로 오류 발생
HR
select sum(salary), avg(salary), max(salary), min(salary), count(salary)
from employees;

HR
select avg(salary), stddev(salary), power(stddev(salary),2), variance(salary), sqrt(variance(salary))
from employees;

-- 사칙연산과 null이 만나면 결과는 무조건 null이다.
HR
select 5600+2838+2345-2346*2343/2353+null
from dual;
-- 그룹함수(집계함수)에서는 null은 무조건 제외하고서 연산을 한다.
HR
select salary * commission_pct
from employees;

HR
select sum(salary * commission_pct)
from employees;

HR
select count(employee_id), count(department_id)
from employees;

-- 킴벨리의 사원번호가 null 이므로 106개로 결과가 출력된다.
전체 사원 수 구해 보기
HR
select count(*)
from employees;

-- employees 테이블에서 기본급여(salary) 의 평균
HR
select sum(salary)/count(salary)
, avg(salary)
, sum(salary)/count(*)
from employees;

-- employees 테이블에서 월급(salary + salary * commission_pct) 의 평균
HR
select sum(salary * commission_pct)/count(salary * commission_pct)
, avg(salary * commission_pct)
, sum(salary * commission_pct)/count(*)
from employees;

-- salary 의 평균과 다르게 결과가 같지 않게 출력된다.
-- 첫 번째와 두 번째의 평균은 분모가 전체 사원이(107개)가 아닌 commission을 받는 사원(35개)들의 평균이 구해진다.
HR
select sum(salary * commission_pct)/count(*)
, avg(nvl(salary * commission_pct, 0))
from employees;

Ⅱ. group by
employees 테이블에서 전체사원들에 대해 부서번호별로 인원수를 나타내세요.
HR
select department_id as 부서번호
, count(*) as 사원수
from employees
group by department_id
order by department_id asc;

employees 테이블에서 남자사원들에 대해 부서번호별로 인원수를 나타내세요.
HR
select department_id as 부서번호
, count(*) as 인원수
from employees
where substr(jubun, 7,1) in('1', '3')
group by department_id
order by department_id;

employees 테이블에서 부서번호별로 그룹을 지은 후, 남자, 여자별로 인원수를 나타내세요.
HR
select department_id as 부서번호
, case when substr(jubun,7,1) in('1','3') then '남' else '여' end as 성별
, count(*) as 인원수
from employees
group by department_id
, case when substr(jubun,7,1) in('1','3') then '남' else '여' end
order by department_id;
HR
select V.department_id AS 부서번호
, V.GENDER AS 성별
, count(*) AS 인원수
from
(
select department_id
, case when substr(jubun,7,1) in('1','3') then '남' else '여' end AS GENDER
from employees
) V
group by V.department_id, V.GENDER
order by department_id;

employees 테이블에서 전체사원들에 대해 부서번호별로 월급의 합계를 나타내세요.
HR
select department_id AS 사원번호
, sum(nvl(salary+salary*commission_pct, salary)) AS "월급의 합계"
from employees
group by department_id
order by department_id;

문제1 ▷▷ employees 테이블에서 남녀별로 월급의 합계와 인원수를 나타내세요.
▷ 첫 번째 방법
HR
select case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS 성별
,sum(nvl(salary+salary*commission_pct, salary)) AS 월급의합계
,count(*) AS 인원수
from employees
group by case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end;

▷ 두 번째 방법
HR
select GENDER AS 성별
, sum(MONTHSAL) AS 월급의합계
, count(*) AS 인원수
from
(
select case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS GENDER
, nvl(salary+salary*commission_pct, salary) AS MONTHSAL
from employees
) V
group by GENDER;

문제2 ▷▷ employees 테이블에서 연령대별 인원수를 나타내세요.
HR
select trunc(AGE, -1) AS 연령대
, count(*) AS 인원수
from
(
select extract(year from sysdate) - (substr(jubun, 1, 2) + case when substr(jubun, 7, 1) in ('1', '2') then 1900 else 2000 end) + 1 AS AGE
from employees
)V
group by trunc(AGE, -1)
order by trunc(AGE, -1);

문제3 ▷▷ employees 테이블에서 연령대별 성별로 인원수를 나타내세요.
HR
select AGELINE AS 연령대
, GENDER AS 성별
, count(*) AS 인원수
from
(
select trunc(extract(year from sysdate) - (substr(jubun, 1, 2) + case when substr(jubun, 7, 1) in ('1', '2') then 1900 else 2000 end) + 1, -1) AS AGELINE
, case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS GENDER
from employees
)V
group by AGELINE, GENDER
order by 1;

문제3 ▷▷ employees 테이블에서 부서번호별 인원수와 평균연령를 나타내세요.
HR
select 부서번호
, round(avg(AGE), 2) AS 평균연령
, count(*) AS 인원수
from
(
select department_id AS 부서번호
, extract(year from sysdate)-(substr(jubun, 1, 2) + (case when substr(jubun, 7,1) in ('1','2') then 1900 else 2000 end)) +1 AS AGE
from employees
) V
group by 부서번호
order by 부서번호;

Ⅲ. having 절
-- group by 절과 함께 사용하는 것으로써 그룹함수에 대한 조건을 사용시 쓰인다.
employess 테이블에서 부서번호별 월급의 평균치가 8000 이상인 부서만 부서번호, 평균월급, 인원수를 나타내세요.
HR
select department_id AS 부서번호
, to_char(trunc(avg(nvl(salary+salary*commission_pct, salary))), '99,999') AS 평균월급
, count(*) AS 인원수
from employees
group by department_id
having trunc(avg(nvl(salary+salary*commission_pct, salary))) >= 8000
order by department_id;

문제 ▷▷ employees 테이블에서 부서번호별 기본급여의 합계가 100000 이상인 부서번호만 부서번호, 인원수, 기본급여합계를 나타내세요.
HR
select department_id AS 부서번호
, count(*) AS 인원수
, sum(salary) AS 기본급여합계
from employees
group by department_id
having sum(salary) >= 100000
order by 1;

문제 ▷▷ 아래의 결과가 나오도록 하세요.
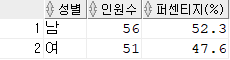
HR
select GENDER AS 성별
, count(*) AS 인원수
, trunc((count(*)/(select count(*) from employees)*100),1) AS "퍼센티지(%)"
from
(
select case when substr(jubun, 7, 1) in('1', '3') then '남' else '여' end AS GENDER
from employees
)V
group by GENDER
order by 1;
group by 절과 함께 사용되어지는 요약값함수 rollup, cube, grouping sets 에 대해서 알아보자.
1. rollup
HR
select department_id, count(*)
from employees
group by rollup(department_id);

-- 12번째의 null : 부서 번호가 존재하지 않는다.
-- 13번째의 null : 그룹을 짓지 않았다. (전체)
2. grouping
HR
select department_id, grouping(department_id), count(*)
from employees
group by rollup(department_id);

-- rollup을 사용할 때 사용되어지는 grouping(department_id)은 0 또는 1이 나오는데 0은 그룹을 지엇다는 뜻이고, 1은 그룹을 안 지었다는 뜻이다.
HR
select case grouping(department_id) when 0 then nvl(to_char(department_id), '인턴') else '전체' end AS 부서번호
, count(*) AS 인원수
from employees
group by rollup(department_id);
HR
select case grouping(department_id) when 0 then nvl(to_char(department_id), '인턴') else '전체' end AS 부서번호
, count(*) AS 인원수
, round(count(*) / (select count(*) from employees) * 100, 1) AS "퍼센티지(%)"
from employees
group by rollup(department_id);

HR
select decode(grouping(department_id), 0, nvl(to_char(department_id), '인턴')
, '전체') AS 부서번호
, decode(grouping(GENDER), 0, GENDER
, '전체') AS 성별
, count(*) AS 인원수
, round(count(*)/(select count(*) from employees)*100, 1) AS "퍼센티지(%)"
from
(
select department_id
, case when substr(jubun, 7, 1) in ('1', '3') then '남' else '여' end AS GENDER
from employees
) V
group by rollup(department_id, GENDER);



